✅ 수업 목표
유명 화가의 화풍을 따라하는 인공지능 만들기
- 이미지 처리하는 방법을 맛본다
- 딥러닝 모델을 사용하는 방법을 이해한다
✅ 딥러닝이란?
- 인간의 뇌와 같이 기계를 만들면 인간과 같이 행동하지 않을까? 라고 생각해서 만든 것이 뉴럴 네트워크
- 뉴런과 같이 모든 네트워크가 서로 이어져 있고 이 구조를 뉴럴 네트워크(딥러닝)라고 한다
딥러닝이 부흥하게 된 이유
- 하드웨어의 발달
- 알고리즘의 향상
- 데이터셋과 공유 네트워크의 발달
딥러닝의 분야
- 자연어처리(Natural Language Processing)
- 이미지처리(Image Processing)
딥러닝 모델과 이미지 다운로드
패키지 불러오기
다운로드 받은 딥러닝 모델 로드하기
import cv2
import numpy as np
net = cv2.dnn.readNetFromTorch('models/eccv16/starry_night.t7')
이미지 출력하기
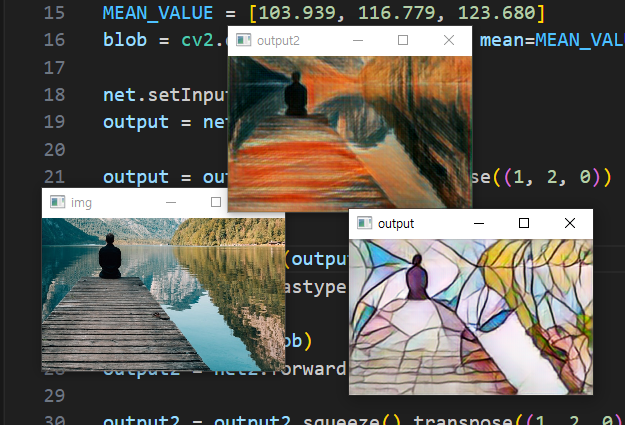
img = cv2.imread('imgs/01.jpg')
cv2.imshow('img', img)
cv2.waitKey(0)
전처리
이미지 전처리하기 (Preprocessing)
전처리(preprocessing)란?
모델의 성능*을 높이기 위해 이미지 전처리라는 방법을 쓴다
딥러닝 모델의 성능이란?
일반적으로는 딥러닝 모델이 얼마나 정답을 잘 맞추는지를 가리키는 정확도를 말한다
여기서는 딥러닝 모델이 얼마나 화풍을 잘 따라하는지!
h, w, c = img.shape
img = cv2.resize(img, dsize=(500, int(h / w * 500)))
print(img.shape) # (325, 500, 3)
MEAN_VALUE = [103.939, 116.779, 123.680]
blob = cv2.dnn.blobFromImage(img, mean=MEAN_VALUE) # 차원 변형
print(blob.shape) # (1, 3, 325, 500)
차원 변형 후 (1, 채널, 높이, 너비) 모양에서 1은 딥러닝에서 배치 사이즈를 의미
딥러닝 모델을 학습시키는 과정에서 이미지를 한 장씩 학습시키지 않고 여러 이미지를 한꺼번에 학습시킨다
만약 이미지를 32개씩 묶어서 학습시킨다면 배치 사이즈는 32 (32, 채널, 높이, 너비)
추론 결과 보기
결과 추론하기 (Inference)
전처리한 이미지(blob)를 모델에 넣고 추론(forward)
output 변수에 추론한 결과가 저장
net.setInput(blob)
output = net.forward()
결과 후처리하기 (Postprocessing)
후처리(postprocessing)란?
이미지를 전처리했듯이 결과값을 후처리하여 다시 이미지로 만드는 과정
# 차원 변형했던 것을 원래대로
output = output.squeeze().transpose((1, 2, 0))
output += MEAN_VALUE # 픽셀 값이 0 미만이거나 255를 초과하는 픽셀이 생길 수 있다
output = np.clip(output, 0, 255) # 범위 넘어가는 값 잘라내기
output = output.astype('uint8') # 정수형(uint8)으로 바꿔줌
새로운 이미지로 다시 추론하기
액자 부분 잘라내기
이미지를 자를 때는 y축부터, x축은 나중에!
img = cv2.imread('imgs/02.jpg')
h, w, c = img.shape
img = cv2.resize(img, dsize=(500, int(h / w * 500)))
img = img[162:513, 185:428]
# y축으로 162 부터 513 까지 자르고, x축으로 185 부터 428까지 자르면 액자 부분만 잘라내짐
잘라낸 이미지만 추론하기
모델을 바꾸려면 readNetFromTorch 에서 모델의 경로만 수정해주면 됨
net = cv2.dnn.readNetFromTorch('models/eccv16/la_muse.t7')
반반 적용하기
import cv2
import numpy as np
net = cv2.dnn.readNetFromTorch('models/instance_norm/mosaic.t7')
# 두번째 모델 로드하기
net2 = cv2.dnn.readNetFromTorch('models/instance_norm/the_scream.t7')
img = cv2.imread('imgs/03.jpg')
h, w, c = img.shape
img = cv2.resize(img, dsize=(500, int(h / w * 500)))
MEAN_VALUE = [103.939, 116.779, 123.680]
blob = cv2.dnn.blobFromImage(img, mean=MEAN_VALUE)
net.setInput(blob)
output = net.forward()
output = output.squeeze().transpose((1, 2, 0))
output += MEAN_VALUE
output = np.clip(output, 0, 255)
output = output.astype('uint8')
# 두번째 모델 추론하기
net2.setInput(blob)
output2 = net2.forward()
output2 = output2.squeeze().transpose((1, 2, 0))
output2 = output2 + MEAN_VALUE
output2 = np.clip(output2, 0, 255)
output2 = output2.astype('uint8')
# 두 개의 결과를 절반으로 잘라 이어 붙이기 # axis=1 x방향으로
output3 = np.concatenate([output[:, :250], output2[:, 250:]], axis=1)
cv2.imshow('output3', output3)
cv2.imshow('img', img)
cv2.imshow('result', output)
cv2.waitKey(0)
숙제
액자 부분만 crop해서 추론하기
더보기
import cv2
import numpy as np
net = cv2.dnn.readNetFromTorch('models/instance_norm/mosaic.t7')
img = cv2.imread('imgs/hw.jpg')
h, w, c = img.shape
img = cv2.resize(img, dsize=(1600, int(h / w * 1600)))
img = img[186:458, 606:1008]
MEAN_VALUE = [103.939, 116.779, 123.680]
blob = cv2.dnn.blobFromImage(img, mean=MEAN_VALUE)
net.setInput(blob)
output = net.forward()
output = output.squeeze().transpose((1, 2, 0))
output += MEAN_VALUE
output = np.clip(output, 0, 255)
output = output.astype('uint8')
cv2.imshow('img', img)
cv2.imshow('result', output)
cv2.waitKey(0)
바뀐 이미지를 다시 액자 안에 집어넣기
cropped_img = img[162:513, 185:428]
# cropped_img로 blob 만들어 추론 -> output
# 다시 끼워 넣기
img[162:513, 185:428] = output
더보기
import cv2
import numpy as np
net = cv2.dnn.readNetFromTorch('models/instance_norm/the_scream.t7')
img = cv2.imread('imgs/hw.jpg')
cropped_img = img[140:370, 480:810]
h, w, c = cropped_img.shape
cropped_img = cv2.resize(cropped_img, dsize=(500, int(h / w * 500)))
print(img.shape)
MEAN_VALUE = [103.939, 116.779, 123.680]
blob = cv2.dnn.blobFromImage(cropped_img, mean=MEAN_VALUE)
print(blob.shape)
net.setInput(blob)
output = net.forward()
output = output.squeeze().transpose((1, 2, 0))
output = output + MEAN_VALUE
output = np.clip(output, 0, 255)
output = output.astype('uint8')
output = cv2.resize(output, (w, h))
img[140:370, 480:810] = output
cv2.imshow('output', output)
cv2.imshow('img', img)
cv2.waitKey(0)
가로로 3개 나누기
더보기
import cv2
import numpy as np
net = cv2.dnn.readNetFromTorch('models/instance_norm/mosaic.t7')
net2 = cv2.dnn.readNetFromTorch('models/instance_norm/the_scream.t7')
net3 = cv2.dnn.readNetFromTorch('models/instance_norm/candy.t7')
cap = cv2.VideoCapture('imgs/03.mp4')
while True:
ret, img = cap.read()
if ret == False:
break
h, w, c = img.shape
img = cv2.resize(img, dsize=(500, int(h / w * 500)))
MEAN_VALUE = [103.939, 116.779, 123.680]
blob = cv2.dnn.blobFromImage(img, mean=MEAN_VALUE)
net.setInput(blob)
output = net.forward()
output = output.squeeze().transpose((1, 2, 0))
output += MEAN_VALUE
output = np.clip(output, 0, 255)
output = output.astype('uint8')
net2.setInput(blob)
output2 = net2.forward()
output2 = output2.squeeze().transpose((1, 2, 0))
output2 += MEAN_VALUE
output2 = np.clip(output2, 0, 255)
output2 = output2.astype('uint8')
net3.setInput(blob)
output3 = net3.forward()
output3 = output3.squeeze().transpose((1, 2, 0))
output3 += MEAN_VALUE
output3 = np.clip(output3, 0, 255)
output3 = output3.astype('uint8')
output = output[0:100, :]
output2 = output2[100:200, :]
output3 = output3[200:, :]
output4 = np.concatenate([output, output2, output3], axis=0)
cv2.imshow('result', output4)
if cv2.waitKey(1) == ord('q'):
break
동영상에 적용해보기
더보기
import cv2
import numpy as np
net = cv2.dnn.readNetFromTorch('models/instance_norm/mosaic.t7')
cap = cv2.VideoCapture('imgs/03.mp4')
while True:
ret, img = cap.read()
if ret == False:
break
MEAN_VALUE = [103.939, 116.779, 123.680]
blob = cv2.dnn.blobFromImage(img, mean=MEAN_VALUE)
net.setInput(blob)
output = net.forward()
output = output.squeeze().transpose((1, 2, 0))
output += MEAN_VALUE
output = np.clip(output, 0, 255)
output = output.astype('uint8')
cv2.imshow('img', img)
cv2.imshow('result', output)
if cv2.waitKey(1) == ord('q'):
break
'딥러닝' 카테고리의 다른 글
| 딥러닝 5주차_흑백사진을 컬러사진으로, 해상도 향상 인공지능 (5) | 2023.05.18 |
|---|---|
| 딥러닝 4주차_얼굴인식 인공지능 스노우 앱 (3) | 2023.05.18 |
| AI 라이브러리 활용 특강 streamlit openai (4) | 2023.05.18 |
| 딥러닝 3주차_마스크 착용 여부, 성별 나이 예측 (2) | 2023.05.18 |
| 딥러닝 1주차_이미지 동영상 처리 (1) | 2023.05.18 |