✅ 수업 목표
오래된 흑백 가족사진, 친구와의 사진을 컬러사진으로 복구하는 인공지능 만들기
- (조금 복잡해진) 이미지 처리하는 방법을 맛본다
- 이미지 컬러시스템 변경하는 방법을 배운다
- 딥러닝 모델을 사용하는 방법을 이해한다
유행하는 이미지 딥러닝 기술 GAN
Generative Adversarial Network (GAN)
서로 적대(Adversarial)하는 관계의 2가지 모델(생성 모델과 판별 모델)을 동시에 사용하는 기술
GPT3 (Generation Pre-trained Transformer 3) : 자연어 처리(NLP) 인공지능 모델
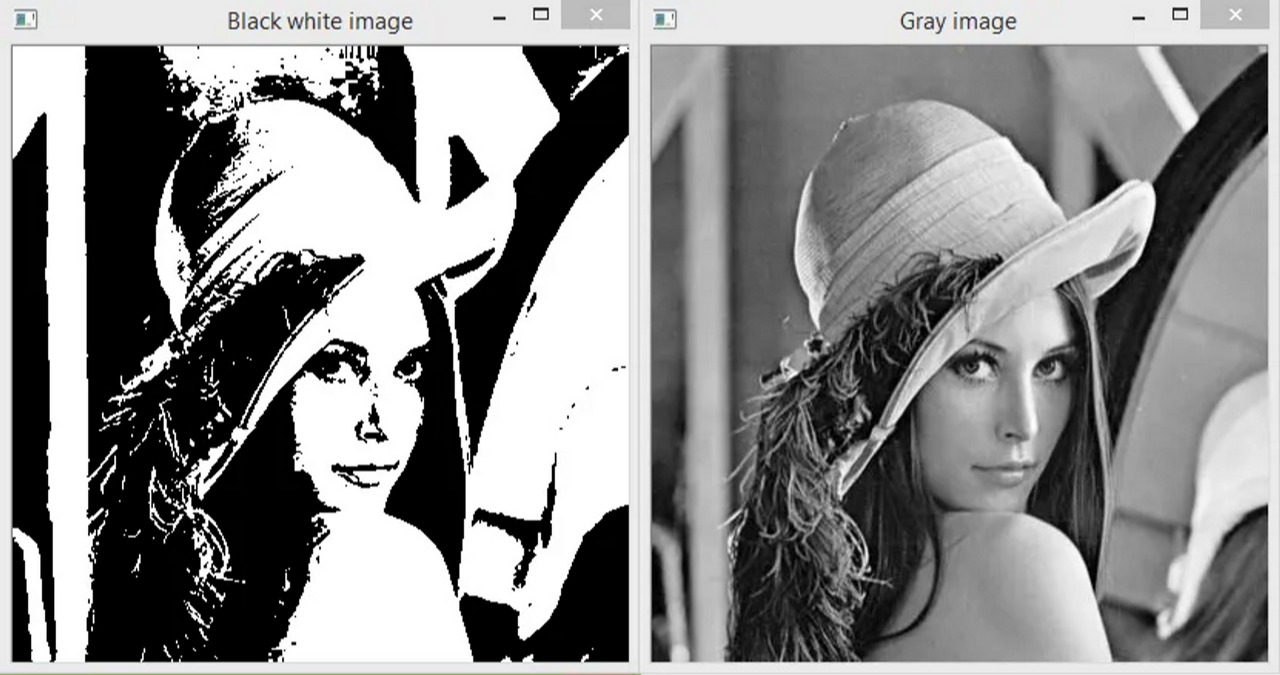
흑백 사진?
이미지 프로세싱 영역에서 흑백(Black and white) 사진이라고 하면
완전한 흰색, 완전한 검은색으로 이루어진 이미지를 말하기 때문에
원래는 회색조(Grayscale) 이미지라고 부르는 것이 맞다
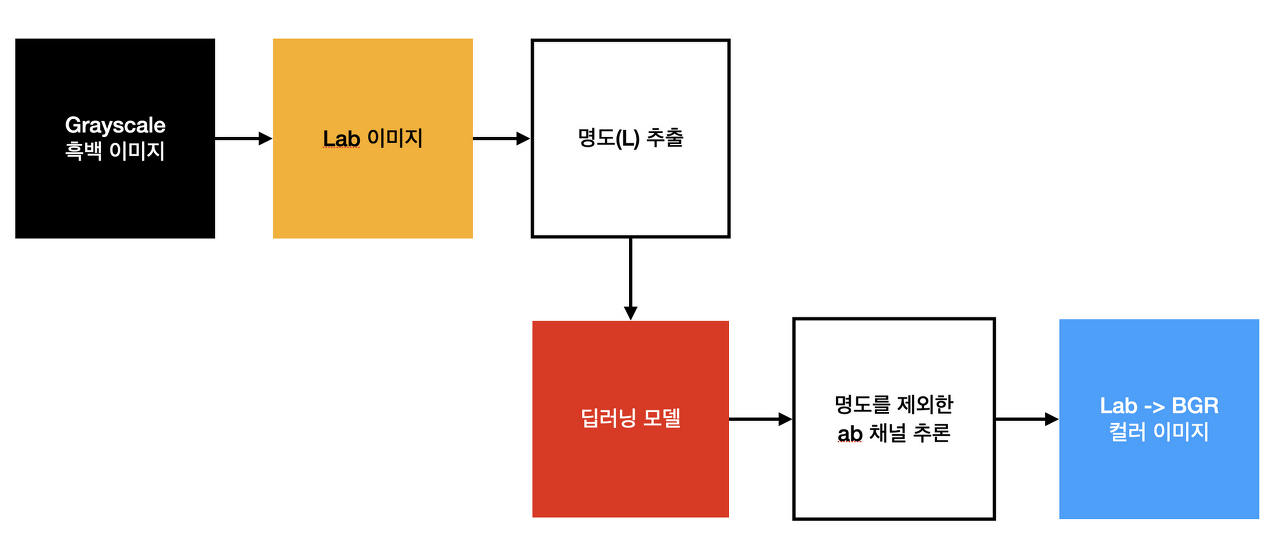
Lab 컬러시스템?
이미지를 Lab 컬러로 변경한 후 L 채널을 입력으로 받아 ab 채널을 예측해내는 모델
Lab 컬러 시스템
L (Luminosity) - 명도, 이미지의 밝기
a - 빨강 / 초록의 보색(a complementary color)축
b - 노랑 / 파랑의 보색(a complementary color)축
패키지 불러오기
import cv2
import numpy as np
모델 로드하기
proto = 'models/colorization_deploy_v2.prototxt'
weights = 'models/colorization_release_v2.caffemodel'
net = cv2.dnn.readNetFromCaffe(proto, weights)
pts_in_hull = np.load('models/pts_in_hull.npy')
pts_in_hull = pts_in_hull.transpose().reshape(2, 313, 1, 1).astype(np.float32)
net.getLayer(net.getLayerId('class8_ab')).blobs = [pts_in_hull]
net.getLayer(net.getLayerId('conv8_313_rh')).blobs = [np.full((1, 313), 2.606, np.float32)]
실제로 중요한 부분은 readNetFromCaffe 함수
이 부분에 모델의 경로를 입력해주는데 prototxt와 weights를 함께 입력해줍니다
Caffe와 마찬가지로 2주차 강의에서 사용한 readNetFromTorch 함수 또한 딥러닝 모델을 만들기 위한 프레임워크.
Torch, Caffe, TensorFlow 같은 딥러닝 프레임워크를 사용해 딥러닝 모델을 만든다
그레이스케일 사진에 색 입히기
이미지 전처리하기
img = cv2.imread('imgs/02.jpg')
h, w, c = img.shape
img_input = img.copy() # 복사
# 전처리 과정
# 기존 정수형(uint8)을 float32(32비트 소수점) 형태로 바꿔라
img_input = img_input.astype('float32') / 255.
img_lab = cv2.cvtColor(img_input, cv2.COLOR_BGR2Lab) # Lab 컬러시스템으로 변경
img_l = img_lab[:, :, 0:1] # L, a, b 채널 중 L 채널만 추출
# resize, mean, 차원변형
blob = cv2.dnn.blobFromImage(img_l, size=(224, 224), mean=[50, 50, 50])
결과 추론하기
net.setInput(blob)
output = net.forward()
결과 후처리하기
# 인간이 이해할 수 있는 형태로 다시 차원 변형
output = output.squeeze().transpose((1, 2, 0))
# 원본 사이즈로 다시 바꿔줌
output_resized = cv2.resize(output, (w, h))
# L 채널 합치기 # 채널 방향으로 합치기 (axis=0세로1가로2채널)
output_lab = np.concatenate([img_l, output_resized], axis=2)
output_bgr = cv2.cvtColor(output_lab, cv2.COLOR_Lab2BGR)
output_bgr = output_bgr * 255
output_bgr = np.clip(output_bgr, 0, 255) # 0-255 잘라내기
output_bgr = output_bgr.astype('uint8') # 정수형으로 변경
결과 출력하기
cv2.imshow('img', img_input)
cv2.imshow('result', output_bgr)
cv2.waitKey(0)


전체 코드
import cv2
import numpy as np
proto = 'models/colorization_deploy_v2.prototxt'
weights = 'models/colorization_release_v2.caffemodel'
net = cv2.dnn.readNetFromCaffe(proto, weights)
pts_in_hull = np.load('models/pts_in_hull.npy')
pts_in_hull = pts_in_hull.transpose().reshape(2, 313, 1, 1).astype(np.float32)
net.getLayer(net.getLayerId('class8_ab')).blobs = [pts_in_hull]
net.getLayer(net.getLayerId('conv8_313_rh')).blobs = [np.full((1, 313), 2.606, np.float32)]
img = cv2.imread('imgs/02.jpg')
h, w, c = img.shape
img_input = img.copy()
img_input = img_input.astype('float32') / 255.
img_lab = cv2.cvtColor(img_input, cv2.COLOR_BGR2Lab)
img_l = img_lab[:, :, 0:1]
blob = cv2.dnn.blobFromImage(img_l, size=(224, 224), mean=[50, 50, 50])
net.setInput(blob)
output = net.forward()
output = output.squeeze().transpose((1, 2, 0))
output_resized = cv2.resize(output, (w, h))
output_lab = np.concatenate([img_l, output_resized], axis=2)
output_bgr = cv2.cvtColor(output_lab, cv2.COLOR_Lab2BGR)
output_bgr = output_bgr * 255
output_bgr = np.clip(output_bgr, 0, 255)
output_bgr = output_bgr.astype('uint8')
cv2.imshow('img', img_input)
cv2.imshow('result', output_bgr)
cv2.waitKey(0)
특정 부분만 컬러로 합성하기
마스크 만들기
# 이미지와 같은 형태로 0으로 채운 이미지 # 사람 눈으로 보면 검은색 이미지
mask = np.zeros_like(img, dtype='uint8')
mask = cv2.circle(mask, center=(260, 260), radius=200, color=(1, 1, 1), thickness=-1)
그레이스케일 이미지와 컬러 이미지 합성
원형 부분은 컬러, 나머지 부분은 그레이스케일 이미지를 만들어 합성
color = output_bgr * mask
gray = img * (1 - mask)
output2 = color + gray
cv2.imshow('result2', output2)

완성 코드
import cv2
import numpy as np
proto = 'models/colorization_deploy_v2.prototxt.txt'
weights = 'models/colorization_release_v2.caffemodel'
net = cv2.dnn.readNetFromCaffe(proto, weights)
pts_in_hull = np.load('models/pts_in_hull.npy')
pts_in_hull = pts_in_hull.transpose().reshape(2, 313, 1, 1).astype(np.float32)
net.getLayer(net.getLayerId('class8_ab')).blobs = [pts_in_hull]
net.getLayer(net.getLayerId('conv8_313_rh')).blobs = [np.full((1, 313), 2.606, np.float32)]
img = cv2.imread('imgs/02.jpg')
h, w, c = img.shape
img_input = img.copy()
img_input = img_input.astype('float32') / 255.
img_lab = cv2.cvtColor(img_input, cv2.COLOR_BGR2Lab)
img_l = img_lab[:, :, 0:1]
blob = cv2.dnn.blobFromImage(img_l, size=(224, 224), mean=[50, 50, 50])
net.setInput(blob)
output = net.forward()
output = output.squeeze().transpose((1, 2, 0))
output_resized = cv2.resize(output, (w, h))
output_lab = np.concatenate([img_l, output_resized], axis=2)
output_bgr = cv2.cvtColor(output_lab, cv2.COLOR_Lab2BGR)
output_bgr = output_bgr * 255
output_bgr = np.clip(output_bgr, 0, 255)
output_bgr = output_bgr.astype('uint8')
mask = np.zeros_like(img, dtype='uint8')
mask = cv2.circle(mask, center=(260, 260), radius=200, color=(1, 1, 1), thickness=-1)
color = output_bgr * mask
gray = img * (1 - mask)
output2 = color + gray
cv2.imshow('img', img_input)
cv2.imshow('result', output_bgr)
cv2.imshow('result2', output2)
cv2.waitKey(0)
해상도 향상 모델
추가 패키지 설치하기
pip install opencv-contrib-python
# window
pip install --user opencv-contrib-python
패키지 로드하기
import cv2
모델 로드하기
Super Resolution
EDSR라는 이름의 모델을 로드.
이미지의 해상도를 3배로 향상시켜주는 모델.
만약 원본 이미지의 크기가 100x100 사이즈였다면 결과 이미지의 크기는 300x300
sr = cv2.dnn_superres.DnnSuperResImpl_create()
sr.readModel('models/EDSR_x3.pb')
sr.setModel('edsr', 3)
이미지 로드하고 추론하기
img = cv2.imread('imgs/06.jpg')
result = sr.upsample(img)
해상도가 낮은 이미지를 로드해주고 sr.upsample() 함수를 사용하여 추론.
이 함수는 전처리와 후처리 과정을 함수에서 해줘서 간편하다
결과 이미지 비교하기
resized_img = cv2.resize(img, dsize=None, fx=3, fy=3)
cv2.imshow('img', img)
cv2.imshow('resized_img', resized_img)
cv2.imshow('result', result)
cv2.waitKey(0)
원본 이미지를 cv2.resize()를 사용하여 가로 3배, 세로 3배의 크기로 늘려준다
n배로 이미지 크기를 변형하고 싶을 때는 dsize 에 None 을 넣고
fx(너비 배수), fy(높이 배수)를 사용하여 이미지 크기를 변형할 수 있다
이 과정을 하는 이유는 기본 알고리즘을 사용하여 이미지의 해상도를 3배 늘렸을 때(resized_img)와
화질향상 딥러닝 모델을 사용하여 이미지의 해상도를 3배 늘렸을 때(result)의 차이를 확인하기 위함


완성 코드
import cv2
sr = cv2.dnn_superres.DnnSuperResImpl_create()
sr.readModel('models/EDSR_x3.pb')
sr.setModel('edsr', 3)
img = cv2.imread('imgs/06.jpg')
result = sr.upsample(img)
resized_img = cv2.resize(img, dsize=None, fx=3, fy=3)
cv2.imshow('img', img)
cv2.imshow('resized_img', resized_img)
cv2.imshow('result', result)
cv2.waitKey(0)
'딥러닝' 카테고리의 다른 글
| 딥러닝 4주차_얼굴인식 인공지능 스노우 앱 (3) | 2023.05.18 |
|---|---|
| AI 라이브러리 활용 특강 streamlit openai (4) | 2023.05.18 |
| 딥러닝 3주차_마스크 착용 여부, 성별 나이 예측 (2) | 2023.05.18 |
| 딥러닝 2주차_유명 화가의 화풍을 따라하는 인공지능 (2) | 2023.05.18 |
| 딥러닝 1주차_이미지 동영상 처리 (1) | 2023.05.18 |