✅ 수업 목표
얼굴인식 인공지능 스노우 앱 만들기
- 실전 영상 처리 기술을 배운다
- 얼굴 영역 탐지 기술을 응용한다
컴퓨터 비전(Computer Vision, CV)이란?
사람과 같이 물체를 보고 인식하는 것
인간이 파악할 수 없는 각 물체가 가지는 Feature(특징)들을 파악하여 규칙을 학습
- 컴퓨터 비전의 역할
- Recognition : 객체 인식
- location : 객체 위치 확인
- Classification : 객체 이미지 분류
- Detection : 객체를 탐지
- Segmentation : 탐지한 객체의 정보를 나누는 일
- 컴퓨터 비전의 종류와 응용
- Object Detection
- YOLO (You Only Look Once)
- Segmentation
- 자율주행 물체인식
- Pose Detection
- Super Resolution
- Style Transfer
- Colorization
패키지 불러오기
Dlib 패키지는 OpenCV와 같이 이미지 처리를 위한 패키지이다
정면 얼굴 탐지 모델을 사용!
이 모델은 속도가 빠르고 사용이 쉽다는 장점이 있다
import cv2
import dlib
모델 로드하기
detector = dlib.get_frontal_face_detector()
영상과 이미지 로드하기
cap = cv2.VideoCapture('videos/01.mp4') # 다운로드 받은 동영상의 경로를 입력
sticker_img = cv2.imread('imgs/sticker01.png', cv2.IMREAD_UNCHANGED) # 배경은 투명
동영상 플레이어부터 만들기
while True:
ret, img = cap.read()
if ret == False:
break
cv2.imshow('result', img)
if cv2.waitKey(1) == ord('q'):
break

전체 코드
더보기
import cv2
import dlib
detector = dlib.get_frontal_face_detector()
cap = cv2.VideoCapture('videos/01.mp4')
sticker_img = cv2.imread('imgs/sticker01.png', cv2.IMREAD_UNCHANGED)
while True:
ret, img = cap.read()
if ret == False:
break
cv2.imshow('result', img)
if cv2.waitKey(1) == ord('q'):
break
얼굴 영역 탐지
얼굴 영역 탐지하기
dets = detector(img)
print("number of faces detected:", len(dets))
# 동영상에 얼굴이 여러 개가 존재할 수 있기 때문에 반복문
for det in dets:
x1 = det.left()
y1 = det.top()
x2 = det.right()
y2 = det.bottom()
cv2.rectangle(img, pt1=(x1, y1), pt2=(x2, y2), color=(255, 0, 0), thickness=2)

스티커 붙이기
overlay_img = sticker_img.copy()
overlay_img = cv2.resize(overlay_img, dsize=(x2 - x1, y2 - y1))
overlay_alpha = overlay_img[:, :, 3:4] / 255.0
background_alpha = 1.0 - overlay_alpha
img[y1:y2, x1:x2] = overlay_alpha * overlay_img[:, :, :3] + background_alpha * img[y1:y2, x1:x2]

스티커의 종류와 크기에 따라 얼굴을 맞춰주는 작업이 필요
스티커의 위치와 크기 조정하기
얼굴 영역이 화면 밖을 벗어나게 되면 에러가 나는 것을 잡아주는 코드
try:
overlay_img = sticker_img.copy()
overlay_img = cv2.resize(overlay_img, dsize=(x2 - x1, y2 - y1))
overlay_alpha = overlay_img[:, :, 3:4] / 255.0
background_alpha = 1.0 - overlay_alpha
img[y1:y2, x1:x2] = overlay_alpha * overlay_img[:, :, :3] + background_alpha * img[y1:y2, x1:x2]
except:
pass
x, y 좌표 조정으로 스티커 크기 맞추기
x1 = det.left() - 40
y1 = det.top() - 50
x2 = det.right() + 40
y2 = det.bottom() + 30

전체 코드
더보기
import cv2
import dlib
detector = dlib.get_frontal_face_detector() # 얼굴 영역 탐지 모델
cap = cv2.VideoCapture('videos/01.mp4')
sticker_img = cv2.imread('imgs/sticker01.png', cv2.IMREAD_UNCHANGED)
while True:
ret, img = cap.read()
if ret == False:
break
dets = detector(img)
print("number of faces detected:", len(dets))
for det in dets:
x1 = det.left() -40
y1 = det.top() -50
x2 = det.right() +40
y2 = det.bottom() +30
# cv2.rectangle(img, pt1=(x1, y1), pt2=(x2, y2), color=(255, 0, 0), thickness=2)
try:
overlay_img = sticker_img.copy()
overlay_img = cv2.resize(overlay_img, dsize=(x2 - x1, y2 - y1))
overlay_alpha = overlay_img[:, :, 3:4] / 255.0
background_alpha = 1.0 - overlay_alpha
img[y1:y2, x1:x2] = overlay_alpha * overlay_img[:, :, :3] + background_alpha * img[y1:y2, x1:x2]
except:
pass
cv2.imshow('result', img)
if cv2.waitKey(1) == ord('q'):
break
랜드마크 탐지
[코드스니펫] 얼굴에 사각형 그리기
import cv2
import dlib
detector = dlib.get_frontal_face_detector()
cap = cv2.VideoCapture('videos/01.mp4')
while True:
ret, img = cap.read()
if ret == False:
break
dets = detector(img)
for det in dets:
try:
x1 = det.left()
y1 = det.top()
x2 = det.right()
y2 = det.bottom()
cv2.rectangle(img, pt1=(x1, y1), pt2=(x2, y2), color=(255, 0, 0), thickness=2)
except:
pass
cv2.imshow('result', img)
if cv2.waitKey(1) == ord('q'):
break
랜드마크 모델 로드하기
predictor = dlib.shape_predictor('models/shape_predictor_5_face_landmarks.dat')
랜드마크 추론하기
랜드마크에 점과 글씨 넣기
이미지의 얼굴 영역 안에서 눈과 코가 어디에 위치하는지 좌표로 알려주기
우리가 로드한 모델에 img와 얼굴위치 좌표 det을 넣어주면 shape 변수에 랜드마크 좌표가 저장된다
for det in dets:
shape = predictor(img, det)
for i, point in enumerate(shape.parts()):
cv2.circle(img, center=(point.x, point.y), radius=2, color=(0, 0, 255), thickness=-1)
cv2.putText(img, text=str(i), org=(point.x, point.y), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=0.8, color=(255, 255, 255), thickness=2)
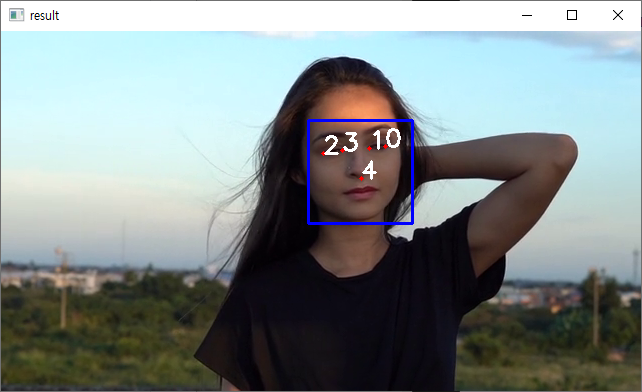
- 0: 오른쪽 눈꼬리
- 1: 오른쪽 눈 안쪽
- 2: 왼쪽 눈꼬리
- 3: 왼쪽 눈 안쪽
- 4: 코 끝
안경 스티커 붙이기
안경 이미지 로드하기
sticker_img = cv2.imread('imgs/glasses.png', cv2.IMREAD_UNCHANGED) # png 이미지
안경의 위치와 크기 계산하기

- 안경의 왼쪽 위 좌표: glasses_x1, glasses_y1
- 안경의 오른쪽 아래 좌표: glasses_x2, glasses_y2
- 안경의 너비와 높이: glasses_w, glasses_h
- 안경의 y축 중심 좌표: center_y
glasses_x1 = shape.parts()[2].x
glasses_x2 = shape.parts()[0].x
h, w, c = sticker_img.shape
glasses_w = glasses_x2 - glasses_x1
glasses_h = int(h / w * glasses_w) # 이미지 비율 유지하면서 사이즈 줄이기
center_y = (shape.parts()[0].y + shape.parts()[2].y) / 2
glasses_y1 = int(center_y - glasses_h / 2)
glasses_y2 = glasses_y1 + glasses_h
안경 크기 조정하기
overlay_img = sticker_img.copy()
overlay_img = cv2.resize(overlay_img, dsize=(glasses_w, glasses_h))
overlay_alpha = overlay_img[:, :, 3:4] / 255.0
background_alpha = 1.0 - overlay_alpha
img[glasses_y1:glasses_y2, glasses_x1:glasses_x2] = overlay_alpha * overlay_img[:, :, :3] + background_alpha * img[glasses_y1:glasses_y2, glasses_x1:glasses_x2]

glasses_x1 = shape.parts()[2].x - 20
glasses_x2 = shape.parts()[0].x + 20

전체 코드
더보기
import cv2
import dlib
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('models/shape_predictor_5_face_landmarks.dat')
cap = cv2.VideoCapture('videos/01.mp4')
sticker_img = cv2.imread('imgs/glasses.png', cv2.IMREAD_UNCHANGED)
while True:
ret, img = cap.read()
if ret == False:
break
dets = detector(img)
for det in dets:
shape = predictor(img, det)
# for i, point in enumerate(shape.parts()):
# cv2.circle(img, center=(point.x, point.y), radius=2, color=(0, 0, 255), thickness=-1)
# cv2.putText(img, text=str(i), org=(point.x, point.y), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=0.8, color=(255, 255, 255), thickness=2)
glasses_x1 = shape.parts()[2].x - 20
glasses_x2 = shape.parts()[0].x + 20
h, w, c = sticker_img.shape
glasses_w = glasses_x2 - glasses_x1
glasses_h = int(h / w * glasses_w)
center_y = (shape.parts()[0].y + shape.parts()[2].y) / 2
glasses_y1 = int(center_y - glasses_h / 2)
glasses_y2 = glasses_y1 + glasses_h
overlay_img = sticker_img.copy()
overlay_img = cv2.resize(overlay_img, dsize=(glasses_w, glasses_h))
overlay_alpha = overlay_img[:, :, 3:4] / 255.0
background_alpha = 1.0 - overlay_alpha
img[glasses_y1:glasses_y2, glasses_x1:glasses_x2] = overlay_alpha * overlay_img[:, :, :3] + background_alpha * img[glasses_y1:glasses_y2, glasses_x1:glasses_x2]
try:
x1 = det.left()
y1 = det.top()
x2 = det.right()
y2 = det.bottom()
cv2.rectangle(img, pt1=(x1, y1), pt2=(x2, y2), color=(255, 0, 0), thickness=2)
except:
pass
cv2.imshow('result', img)
if cv2.waitKey(1) == ord('q'):
break
숙제
전체 코드
더보기
import cv2
import dlib
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('models/shape_predictor_5_face_landmarks.dat')
cap = cv2.VideoCapture('videos/02.mp4')
sticker_img = cv2.imread('imgs/pig.png', cv2.IMREAD_UNCHANGED)
while True:
ret, img = cap.read()
if ret == False:
break
dets = detector(img)
for det in dets:
shape = predictor(img, det)
try:
x1 = det.left()
y1 = det.top()
x2 = det.right()
y2 = det.bottom()
# compute pig nose coordinates
center_x = shape.parts()[4].x
center_y = shape.parts()[4].y - 5
h, w, c = sticker_img.shape
nose_w = int((x2 - x1) / 4)
nose_h = int(h / w * nose_w)
nose_x1 = int(center_x - nose_w / 2)
nose_x2 = nose_x1 + nose_w
nose_y1 = int(center_y - nose_h / 2)
nose_y2 = nose_y1 + nose_h
# overlay nose
overlay_img = sticker_img.copy()
overlay_img = cv2.resize(overlay_img, dsize=(nose_w, nose_h))
overlay_alpha = overlay_img[:, :, 3:4] / 255.0
background_alpha = 1.0 - overlay_alpha
img[nose_y1:nose_y2, nose_x1:nose_x2] = overlay_alpha * overlay_img[:, :, :3] + background_alpha * img[nose_y1:nose_y2, nose_x1:nose_x2]
except:
pass
cv2.imshow('result', img)
if cv2.waitKey(1) == ord('q'):
break

'딥러닝' 카테고리의 다른 글
| 딥러닝 5주차_흑백사진을 컬러사진으로, 해상도 향상 인공지능 (5) | 2023.05.18 |
|---|---|
| AI 라이브러리 활용 특강 streamlit openai (4) | 2023.05.18 |
| 딥러닝 3주차_마스크 착용 여부, 성별 나이 예측 (2) | 2023.05.18 |
| 딥러닝 2주차_유명 화가의 화풍을 따라하는 인공지능 (2) | 2023.05.18 |
| 딥러닝 1주차_이미지 동영상 처리 (1) | 2023.05.18 |