✅ 수업 목표
- 머신러닝/딥러닝의 개념을 가볍게 이해한다
- 이미지/영상 처리를 위한 파이썬 라이브러리 종류를 살펴본다
- 컴퓨터가 보는 이미지 데이터가 어떻게 생겼는지 살펴본다
- 이미지와 비디오를 화면에 출력한다
✅ 필수 프로그램 설치
패키지들을 미리 준비해 놓은 배포판 패키지인 아나콘다
Anaconda 설치 및 가상환경 설치하기 https://www.anaconda.com/download
아나콘다 하나만 설치하면 파이썬 뿐만 아니라 Tensorflow, OpenCV, Dlib까지 모두 설치 가능

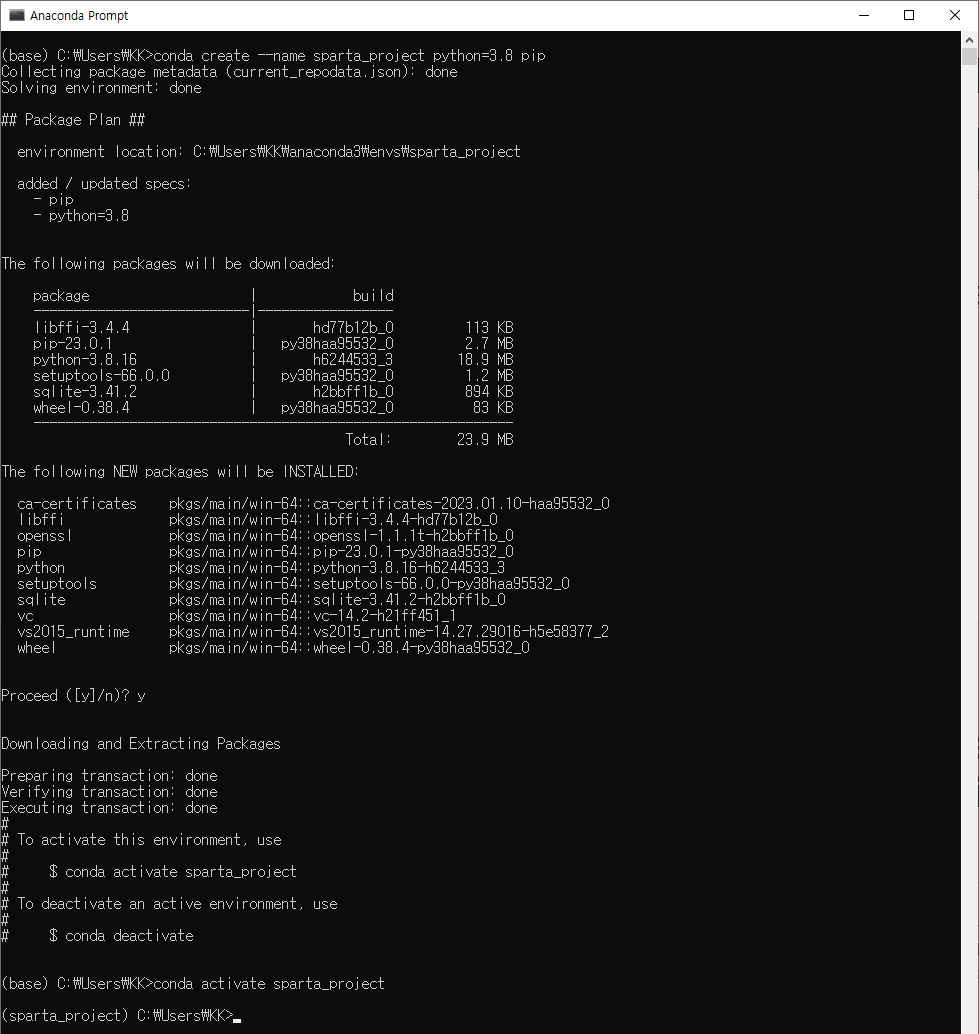
# 아나콘다 가상환경 설정하기
conda create --name sparta_project python=3.8 pip
Proceed ( [y] / n )?
>>> y 입력
# 가상환경 활성화
conda activate sparta_project
>>> (sparta_project) 뜨면 OK
# 아나콘다 자체 패키지 관리자인 conda 패키지 최신 버전으로 업데이트
conda update -n base conda
# 파이썬과 관련된 패키지 모두 업데이트
conda update --all
Tensorflow
알파고를 탄생시킨 구글에서
딥러닝과 머신러닝을 일반인들이 쉽게 사용할 수 있도록
오픈소스로 공개한 라이브러리
# tensorflow 및 라이브러리를 설치
pip install tensorflow
OpenCV
CV는 Computer Vision을 의미
컴퓨터 비전이란 딥러닝 분야의 일종으로 사람과 같이 물체를 보고 인식하는 것을 의미
pip install opencv-python
Dlib
OpenCV와 마찬가지로 Computer Vision에 사용되는 라이브러리
conda install -c conda-forge dlib
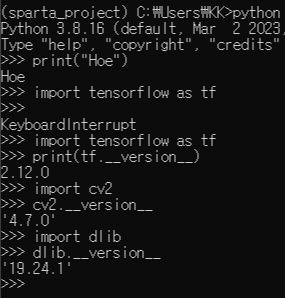
패키지 설치 버전 확인하기
Anaconda3 Prompt에서
만약 가상환경이 켜져 있지 않은 경우, conda activate sparta_project 을 입력한 후 시작
# Python
>>> python
>>> print("Hello, world!")
# Tensorflow
>>> import tensorflow as tf
tensorflow라는 라이브러리를 tf로 간단하게 줄여서 명명하겠다라는 의미
입력시 Warning이 나온다면 GPU세팅 및 CUDA를 설치하지 않았다는 것
>>> print(tf.__version__)
# OpenCV
>>> import cv2
>>> cv2.__version__
딥러닝
머신러닝 방법 중 하나
알고리즘 수학과 컴퓨터 과학, 언어학 또는 관련 분야에서 어떠한 문제를 해결하기 위해
정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것, 계산을 실행하기 위한 단계적 절차
머신러닝(기계학습)이라는 포괄적인 범위 안에 딥러닝(Deep learning 깊은? 학습)이 포함되어 있다
연구 초반에는 MLP(Multi-Layer Perceptron)이라고 불렸으나
사람들의 유행을 타기 시작하면서 어감이 좋은 딥러닝으로 굳어지게 되었다
머신러닝 중에서도 고차원의 비선형 문제를 잘 풀 수 있는 딥러닝 기술이 발전하기 시작했다
대표적인 딥러닝 모델 종류
Deep Feedforward Network (DFN)
풀리 커넥티드
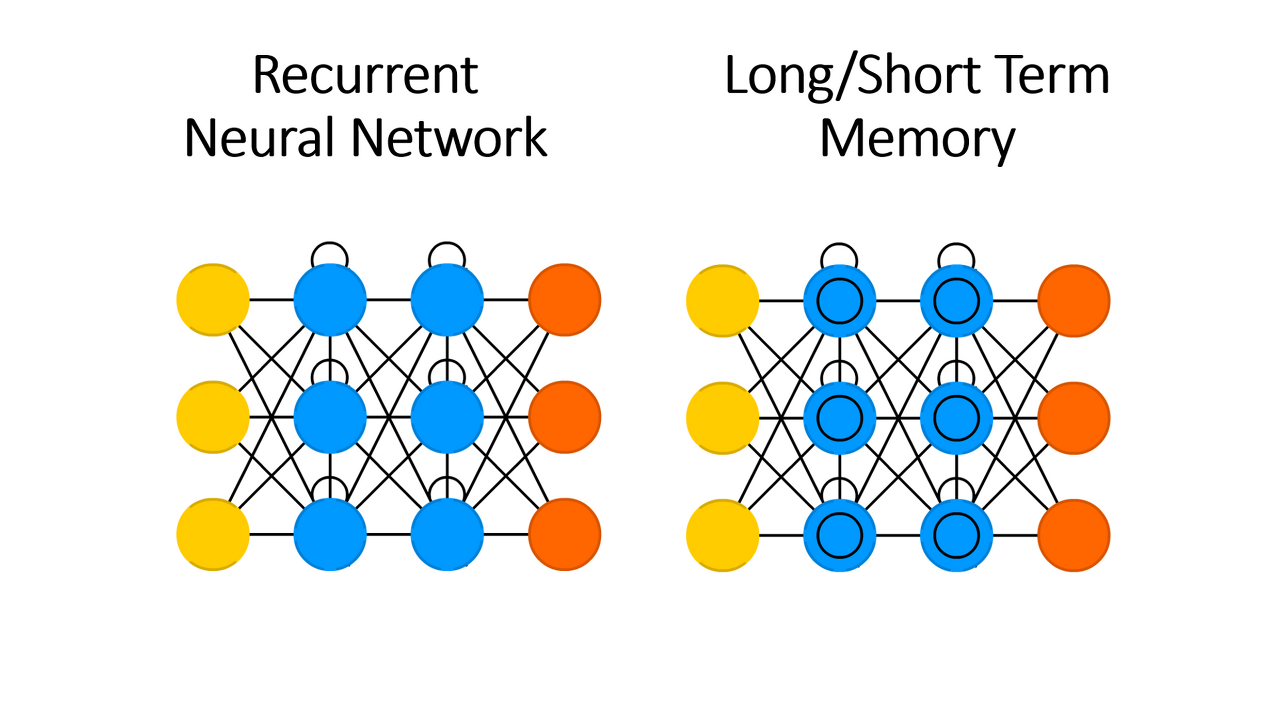
Recurrent Neural Network (RNN)과 Long/Short Term Memory (LSTM)
시간이 관련된 데이터나 자연어 처리에 주로 쓰인다
Convolutional Neural Network (CNN)
DFN의 발전형
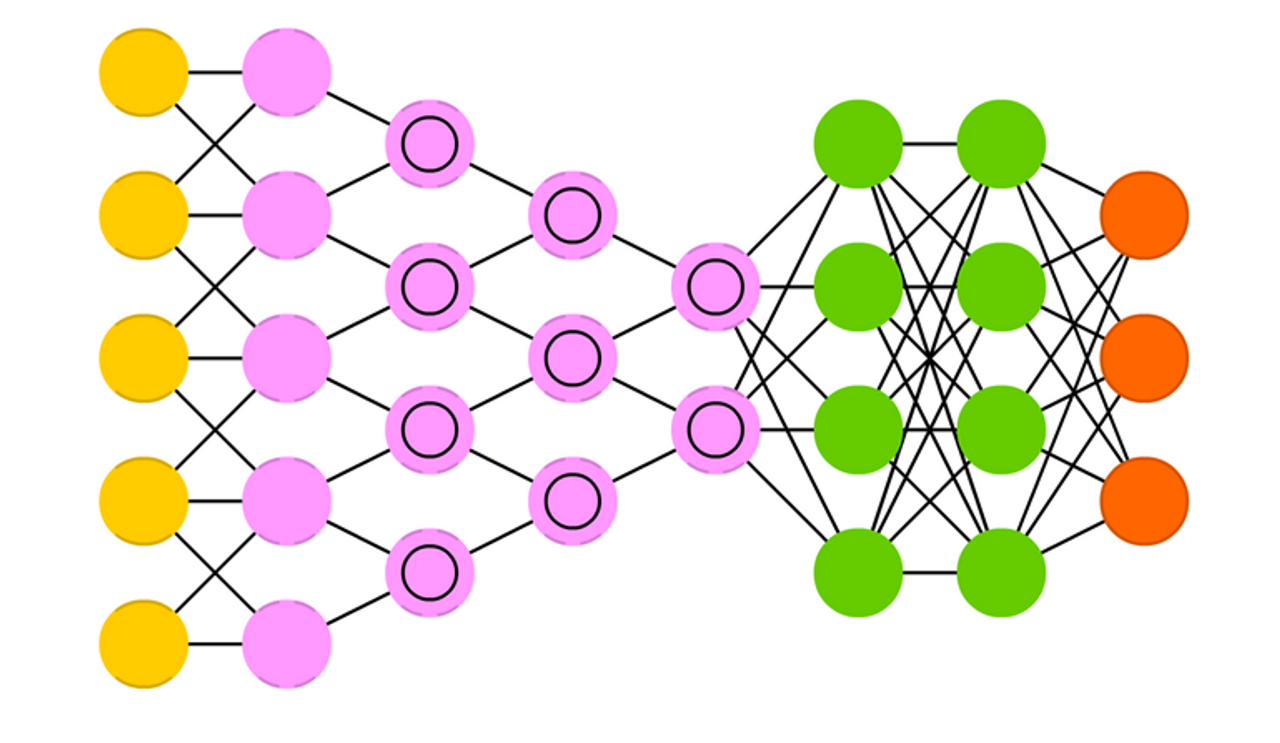
Generative Adversarial Network (GAN)
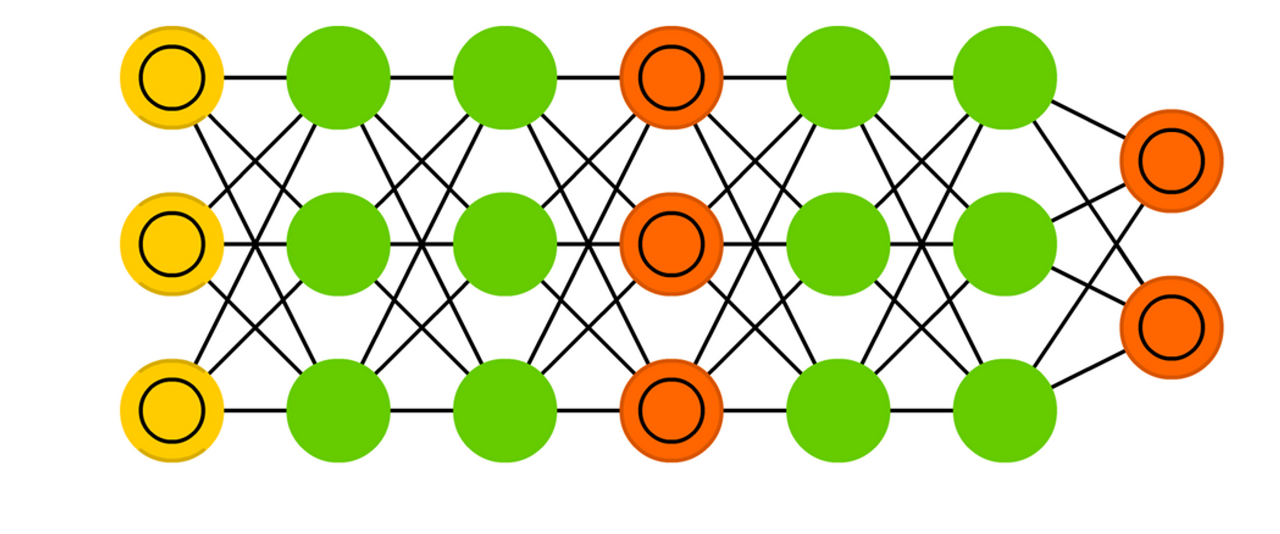
딥러닝을 위한 파이썬 기초
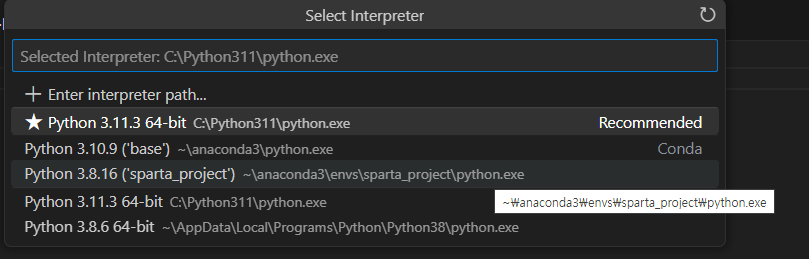
Python 3.8.16 ('sparta_project') 선택
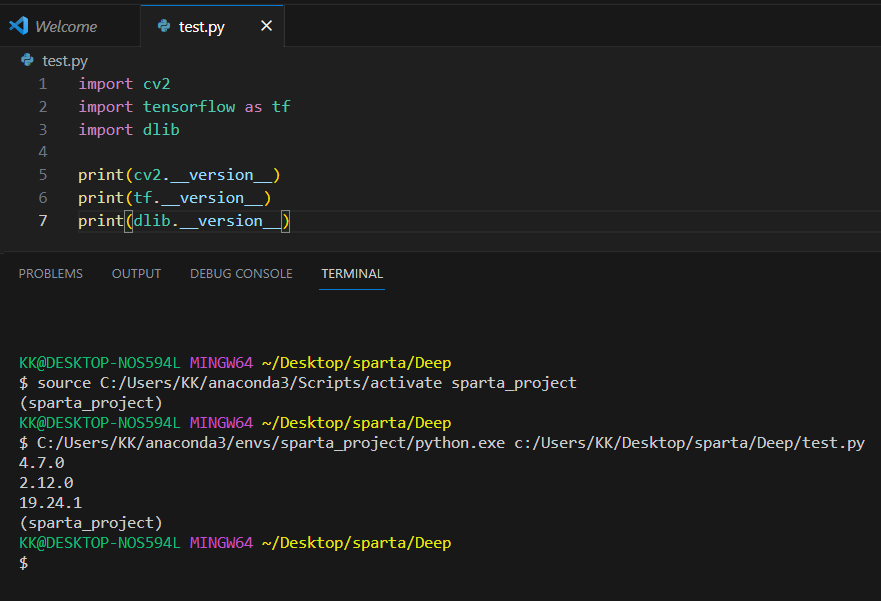
패키지 불러오기
OpenCV(Open Source Computer Vision) 패키지 안에는
사진과 동영상 파일을 로드하고 편집할 수 있는 기능들이 들어있다
import cv2 # cv2 : OpenCV의 패키지 이름
import tensorflow as tf
import dlib
print(cv2.__version__)
print(tf.__version__)
print(dlib.__version__)
이미지 처리
OpenCV로 이미지 보기
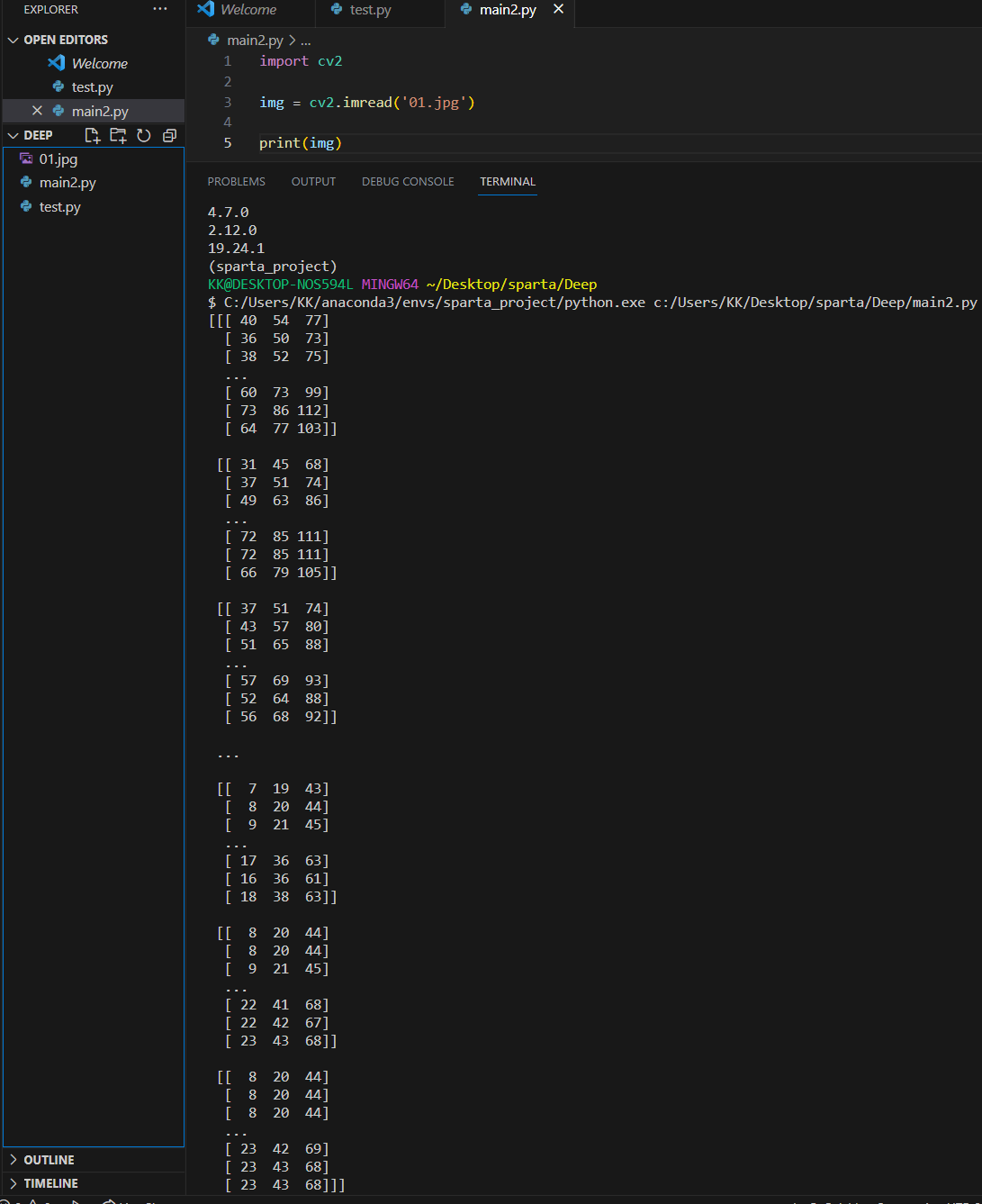
컴퓨터가 보는 사진(이미지)의 형태는 "숫자"
import cv2
img = cv2.imread('01.jpg')
print(img)
이미지 형태 보기
인간은 사진 파일을 2차원으로 인식하지만, 컴퓨터는 3차원으로 인식한다
print(img.shape) # (404, 640, 3) = (높이, 너비, 채널)
BGR은 빛의 삼원색과 같다
이미지는 여러개의 픽셀(점)로 이루어져 있으며 각 픽셀은 BGR의 정보를 포함하고 있다
각 픽셀의 BGR은 0에서 255까지의 값을 가지며 BGR을 적절히 섞어 다양한 색깔을 표현한다
이미지 미리보기
# image show의 약자
# 'result' : 이미지를 띄우는 창의 이름
# img는 이미지
cv2.imshow('result', img)
cv2.waitKey(0) # 아무 키를 입력할 때까지 이미지를 띄운 창이 사라지지 않는다
이미지 처리 기초
이미지 위에 도형 그리기
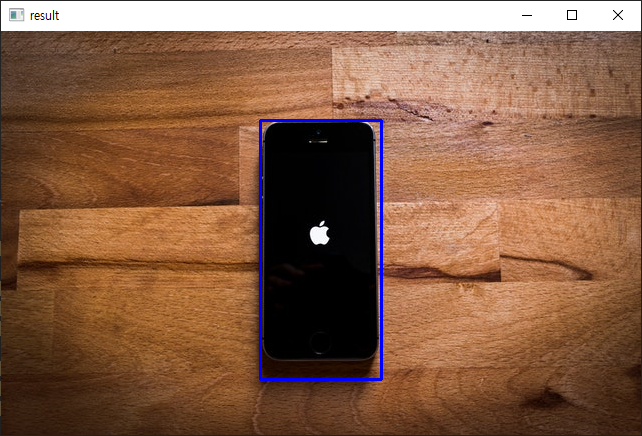
사각형 그리기
# pt1 : 왼쪽 위 좌표 (맨 왼쪽 맨 위가 0, 0)
# pt2 : 오른쪽 아래 좌표
cv2.rectangle(img, pt1=(259, 89), pt2=(380, 348), color=(255, 0, 0), thickness=2)
cv2.imshow('result', img) # 얘 위에
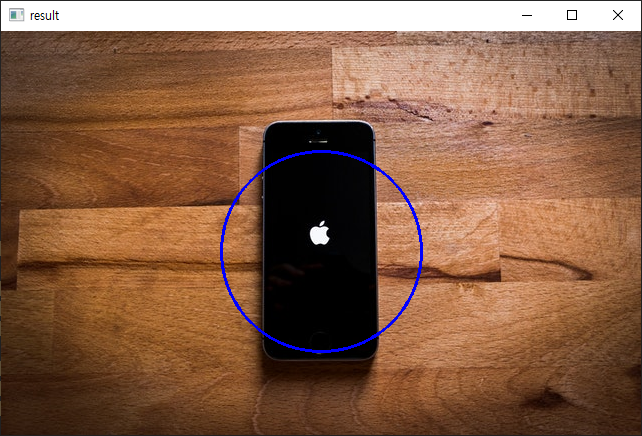
원 그리기
# center : 원의 중심 좌표
# radius : 원의 반지름
# 속을 채우고 싶을 때 : thickness에 음수(-1, -2, -10, ...)
cv2.circle(img, center=(320, 220), radius=100, color=(255, 0, 0), thickness=2)
cv2.imshow('result', img)
이미지 만져보기
이미지 자르기 (crop)
직사각형 형태로만 자르기가 가능
cropped_img = img[89:348, 259:380]
cv2.imshow('cropped', cropped_img)
이미지를 자를 때는 y, x 순서로 쓴다
이유는 OpenCV가 이미지를 저장할 때 기본적으로 numpy 를 쓰기 때문
C 스타일의 언어에서는 y → x 순서로 사용하고 Fortran 스타일의 언어에서는 x → y 로 사용
이미지 크기 변경하기 (resize)
모델을 학습시킬 때 이미지의 크기를 고정해야 성능이 좋기 때문
img_resized = cv2.resize(img, (512, 256))
cv2.imshow('resized', img_resized)
cv2.waitKey(0)
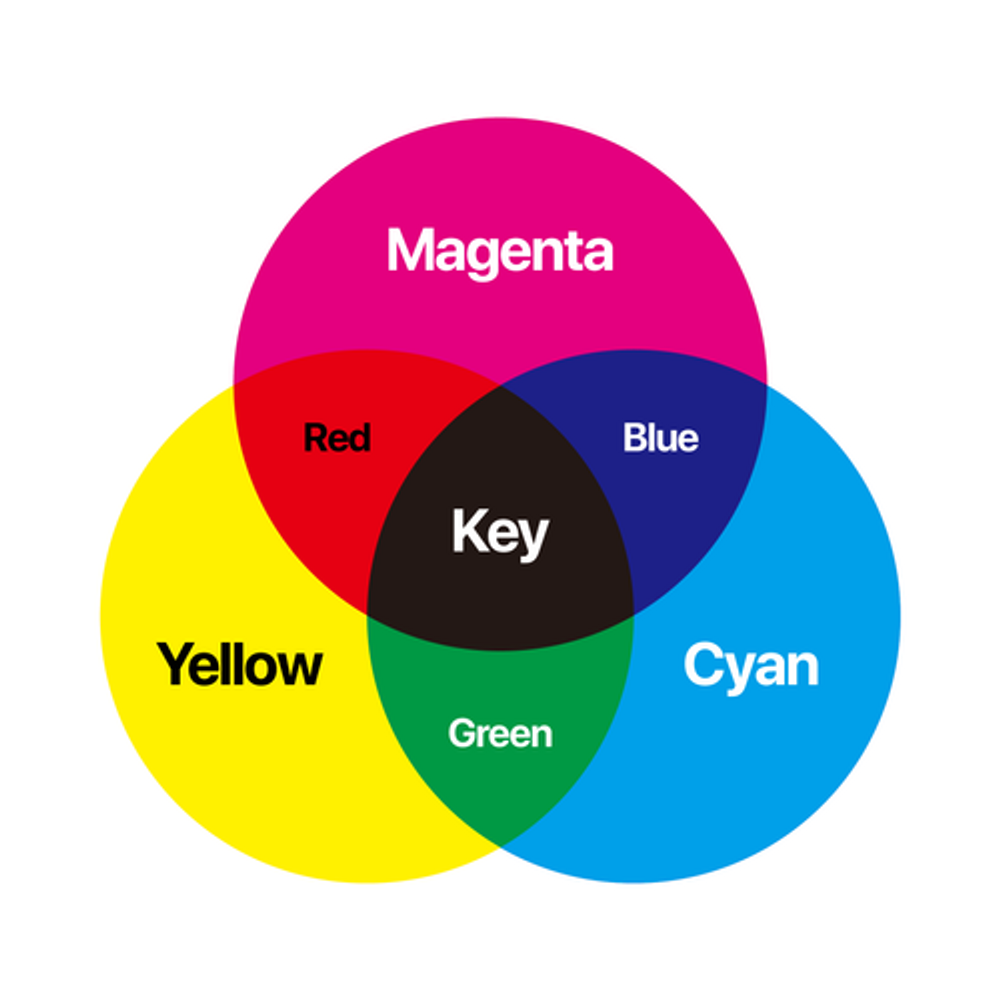
이미지 컬러 시스템 바꾸기
컬러 시스템은 색깔을 표현하는 방법
예를들면 BGR(파랑색, 초록색, 빨간색) 의 3가지 색깔을 섞어 색깔을 표현할 수도 있고
CMYK(하늘색, 분홍색, 노랑색, 검정색)의 4가지 색깔을 섞어 색깔을 표현할 수 있다
기본적으로 BGR 시스템을 주로 사용하지만 경우에 따라 RGB 시스템이나 Lab 시스템을 사용해야 하는 경우도 있다
# BGR2RGB : BGR → RGB로 컬러시스템 변경
# BGR2GRAY : 흑백
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
cv2.imshow('result', img_rgb)
cv2.waitKey(0)
이미지 처리 심화
배경 이미지 위에 다른 이미지를 합성하기 (Overlay)
import cv2
img = cv2.imread('01.jpg')
overlay_img = cv2.imread('dices.png', cv2.IMREAD_UNCHANGED) # 투명
배경 이미지와 오버레이 이미지는 똑같이 cv2.imread() 를 사용하여 이미지를 로드해오지만
주사위 이미지에는 cv2.IMREAD_UNCHANGED 를 뒤에 붙여준다
오버레이 이미지는 확장자가 .png 인 배경이 투명한 이미지여야 한다
cv2.imread()를 사용하여 png 이미지를 로드할 때는
꼭 cv2.IMREAD_UNCHANGED를 붙여줘야 배경 투명도를 유지한 상태로 로드가 된다
이미지 크기 변환하기
# 가로 크기 150픽셀, 세로 크기 150픽셀로 변환
overlay_img = cv2.resize(overlay_img, dsize=(150, 150))
투명도를 이용하여 이미지 끼워맞추기
투명도(Alpha)란? 각 픽셀이 얼마나 투명한지 나타내는 값!
완전히 투명하면 0, 불투명하다면 255.
img는 원래 3채널, overlay_img는 4채널
BGR에 A까지 더해, 총 4개 채널을 이용하면
색 뿐만 아니라 반투명한 이미지, 바탕만 투명한 이미지와
픽셀의 색이 진할수록 불투명한 이미지 등 다양한 투명도를 나타낼 수 있다
아래는 배경 이미지와 오버레이 이미지를 끼워맞추기 위해 필요한 코드
# overlay_img[:, :, 3:] → 높이, 너비, 채널(4번째 채널만 자르기 위해 :3)
overlay_alpha = overlay_img[:, :, 3:] / 255.0
background_alpha = 1.0 - overlay_alpha
이미지 합성하기
x1, y1, x2, y2 좌표를 사용하여 오버레이 이미지의 위치와 크기를 지정
x1 = 100
y1 = 100
x2 = x1 + 150
y2 = y1 + 150
img[y1:y2, x1:x2] = overlay_alpha * overlay_img[:, :, :3] + background_alpha * img[y1:y2, x1:x2]
# overlay_img[:, :, :3] → 3까지만 자르므로 색깔 정보만 가져옴
완성 코드
import cv2
img = cv2.imread('01.jpg')
overlay_img = cv2.imread('dices.png', cv2.IMREAD_UNCHANGED)
overlay_img = cv2.resize(overlay_img, dsize=(150, 150))
overlay_alpha = overlay_img[:, :, 3:] / 255.0
background_alpha = 1.0 - overlay_alpha
x1 = 100
y1 = 100
x2 = x1 + 150
y2 = y1 + 150
img[y1:y2, x1:x2] = overlay_alpha * overlay_img[:, :, :3] + background_alpha * img[y1:y2, x1:x2]
cv2.imshow('result', img)
cv2.waitKey(0)
동영상 처리
동영상 출력하기 - 동영상 플레이어 만들기
동영상은 이미지의 연속
import cv2
cap = cv2.VideoCapture('04.mp4')
# 동영상 파일을 불러올 때
# 괄호 안에 동영상 파일의 경로를 입력하면 해당 영상 파일을 로드
# cap = cv2.VideoCapture(0) → 0번 디바이스에 연결
# 이미지를 한 프레임씩 읽고 출력하는 코드를 무한하게 반복
while True:
ret, img = cap.read()
if ret == False: # 영상에서 제대로 프레임을 읽어 왔을 때 True
break
cv2.imshow('result', img)
# 1ms(0.001초)
# q 누르면 무한루프에서 빠져나와 프로그램 종료
if cv2.waitKey(1) == ord('q'):
break
동영상 처리 심화
영상에서 도형 출력하기
cv2.rectangle(img, pt1=(721, 183), pt2=(878, 465), color=(255, 0, 0), thickness=2)
영상 그레이스케일로 만들기
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
영상 크기 변환하기 (Resize)
img = cv2.resize(img, dsize=(640, 360))
영상 자르기 (Crop)
img = img[100:200, 150:250]
'딥러닝' 카테고리의 다른 글
| 딥러닝 5주차_흑백사진을 컬러사진으로, 해상도 향상 인공지능 (5) | 2023.05.18 |
|---|---|
| 딥러닝 4주차_얼굴인식 인공지능 스노우 앱 (3) | 2023.05.18 |
| AI 라이브러리 활용 특강 streamlit openai (4) | 2023.05.18 |
| 딥러닝 3주차_마스크 착용 여부, 성별 나이 예측 (2) | 2023.05.18 |
| 딥러닝 2주차_유명 화가의 화풍을 따라하는 인공지능 (2) | 2023.05.18 |