자료구조/알고리즘을 배워야 하는 이유
성능, 용량, 비용
자료(데이터)를 효율적으로 관리하는 방법
시간 복잡도와 공간 복잡도
내가 작성한 코드의 성능, 용량을 판단하기 위한 척도
시간 복잡도:
수행시간(성능)의 척도
빅오(Big-O) 표기법:
제한 시간과 제한 사항(데이터의 크기)
대략 연산 1억번에 1초
for문 하나 있으면 O(n)
for문 하나 있으면 O(n^2)
for문 하나 있으면 O(n^3)
...
예)
알고리즘 A의 시간 복잡도는 O(nlogn)
알고리즘 B의 시간 복잡도는 O(n^2)
공간 복잡도:
메모리 사용량의 척도
최선일 경우(best case) : 빅-오메가 표기법
보통일 경우( case) : 빅- 표기법
최악일 경우(worst case) : 빅-오 표기법
but, 메모리 기술의 발달로 인해
중요도 : 시간복잡도 > 공간복잡도
연결 리스트(linked list)
유동적으로 연결 고리를 뗐다 붙였다 할 수 있음
노드 - 각 화물칸. 맨 앞의 노드를 Head, 맨 뒤의 노드를 Tail.
포인트 - 현재 화물칸이 가리키는 다음 화물칸
스택과 큐
데이터를 임시 저장하고 싶을 때

스택
한쪽 끝이 막혀 있는 통과 같은 자료구조
파이썬에서는 주로 리스트로 사용
push : 자료를 쌓는 것 ()
pop : 맨 마지막 자료부터 빼는 것 (후입선출, Last-In-First-Out, LIFO)
peek : 맨 마지막 자료를 반환하지만 제거하지는 않는 것
- 매개 변수, 지역 변수 : 최근 임시 저장한 데이터를 먼저 사용하고 싶을 때
- 문자열 괄호((())) : 쌍을 맞춰 데이터를 임시 저장하고 싶을 때
문자열을 순회하며 ( : push, ) : pop → 순회가 끝나고 스택이 비어 있다면 올바른 괄호
- 뒤로 가기 기능을 만들고 싶을 때
큐
양쪽 끝이 뚫려 있는 통과 같은 자료구조
처음 자료부터 빠짐
enqueue
dequeue : 먼저 들어온 자료부터 먼저 나옴 (선입선출, First-In-First-Out, FIFO)
- 데이터를 임시 저장하고 차례로 꺼내고 싶을 때 (버퍼의 기능)
- 원형 큐 : 원형으로 이루어진 큐
- 덱(Double-Ended Queue, Deque) : 양쪽에서 데이터 삽입, 삭제가 가능한 큐
- 우선순위 큐(이진트리) : 저장된 순서와 상관없이 우선순위가 높은 데이터가 먼저 나가는 큐
정렬 알고리즘
데이터를 정해진 기준에 따라 재배치하는 것
정렬 알고리즘에 따라 시간복잡도가 다르다
- 삽입 정렬(O(n^2)) : 앞에서부터 차례로 비교해 자신의 위치를 찾아 삽입
- 버블 정렬(O(n^2)) : 인접한 요소와 비교하며 바꿔치기(가장 큰 원소 제외하고 다시 정렬을 반복 - 거품이 위로 올라가듯)
- 선택 정렬(O(n^2)) : 요소들 중 최소값을 찾아 맨 처음 값과 바꿔 나머지 요소들이 정렬될 때까지 반복
- 퀵 정렬(O(nlogn)) : 빠르다. 분할정복(divide-and-conquer) 알고리즘 - 큰 문제를 작은 분리하여 작은 문제들을 해결함으로써 큰 문제를 해결. 리스트에서 한 요소(피벗)을 골라 작은 원소들은 앞으로, 큰 원소들은 뒤로 나눠 재귀적으로 반복
sort와 sorted의 차이
sorted() : 배열의 값 자체를 바꾸지는 않는다
# 오름차순
my_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
sorted_list = sorted(my_list)
print(sorted_list) # [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
print(my_list) # [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# 내림차순
my_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
sorted_list = sorted(my_list, reverse=True)
print(sorted_list) # [9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
print(my_list) # [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
sort() : 배열의 값 자체를 바꾼다
# 오름차순
my_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
my_list.sort()
print(my_list) # [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
# 내림차순
my_list.sort(reverse=True)
print(my_list) # [9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
기본 코드 작성 능력
이차원 배열
1 2 3
4 5 6
7 8 9
이차원 배열을 선언한 뒤 위와 동일하게 출력하기
a = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
for x, y, z in a:
print(x, y, z)
arr = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
for row in arr:
print(*row)
arr = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
for row in arr:
for element in row:
print(element, end=" ") #숫자 사이 띄우기
print() # 줄 바꾸기
가운데 글자 반환하는 함수 만들기
def middle(s):
answer = ''
if len(s) % 2 == 0:
answer = s[len(s)//2-1] + s[len(s)//2]
else:
answer = s[len(s)//2]
return answer
s1 = "abcde"
print(middle(s1)) # c
s2 = "qwer"
print(middle(s2)) # we
랜덤 숫자 맞추기
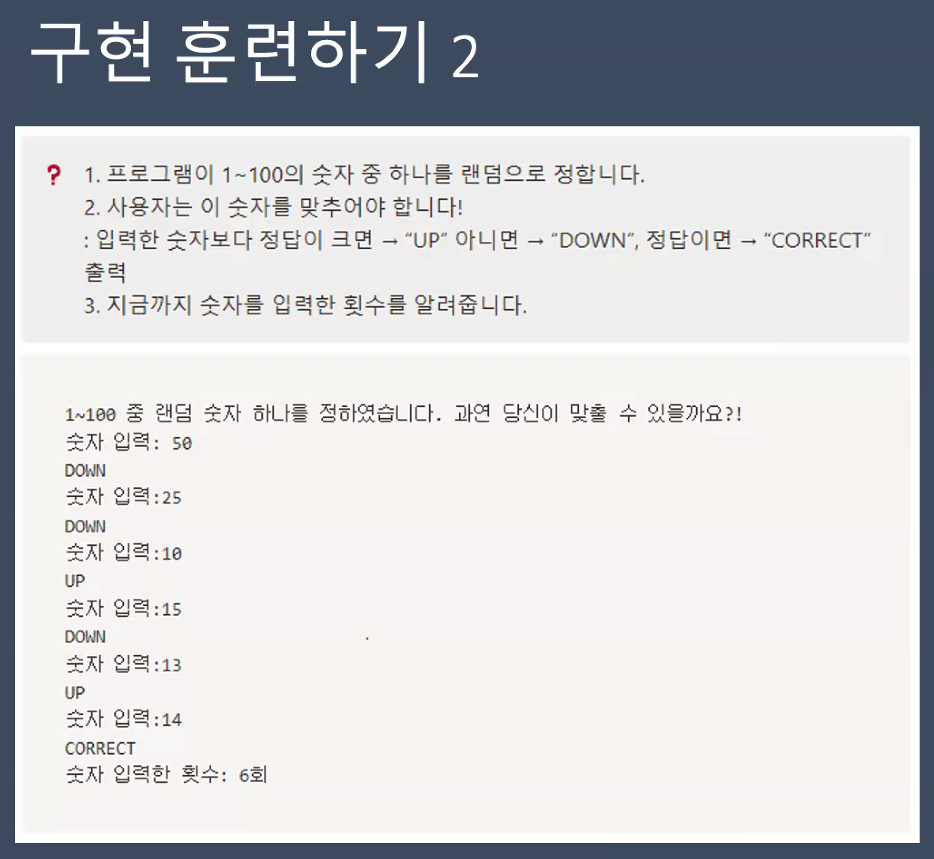
import random
answer = random.randint(1, 100)
count = 0
num = 0
def find_num(num):
global count
print(answer)
while answer != num:
num = int(input("1~100 중에서 숫자 입력: "))
count += 1
if answer > num:
print("UP")
elif answer < num:
print("DOWN")
elif answer == num:
print("CORRECT\n"+str(count)+"번만에 맞췄습니다!")
find_num(num)